Alibaba open sourced the new generation of Tongyi Qianwen model Qwen3. It is reported that its number of parameters is only one-third of DeepSeeker R1, which significantly reduces the cost, but its performance is good.
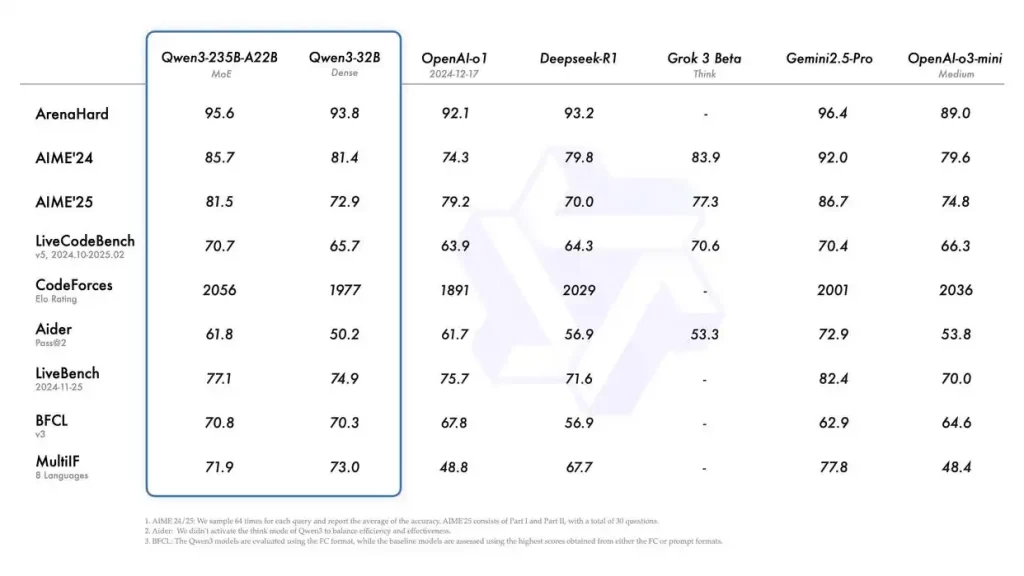
The report shows that Qwen3-235B-A22B outperforms top global models such as DeepSeek-R1, o1, o3-mini, Grok-3, and Gemini-2.5-Pro in benchmark tests for code, mathematics, and general abilities. Becoming the world’s strongest open-source model.
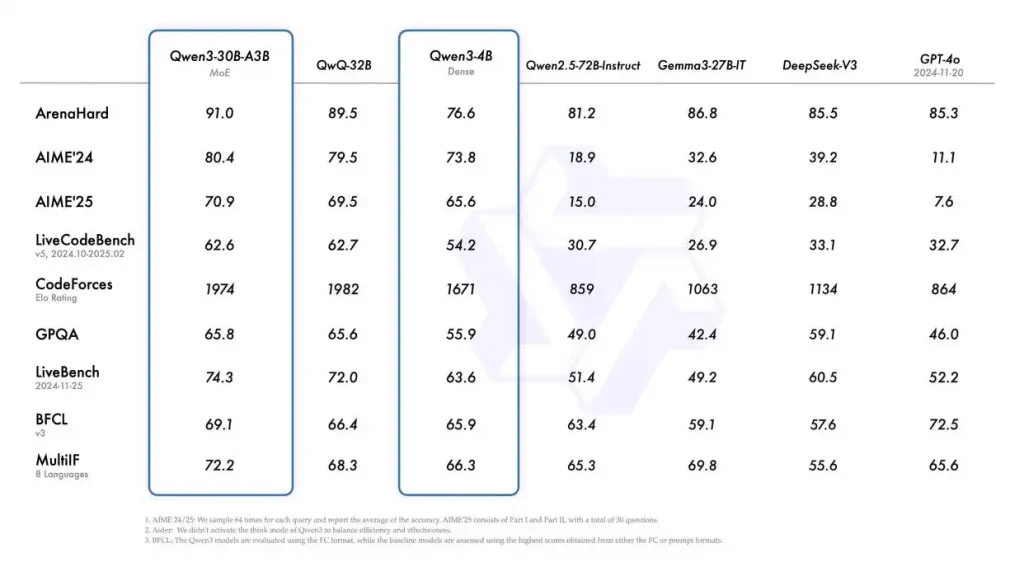
By improving the model architecture, increasing the training data, and implementing more effective training methods, Qwen3 has achieved better performance than the larger parameter scale Qwen2.5 base model even with a smaller model size. Especially in STEM, coding, and reasoning fields, the performance of the Qwen3 Dense base model even surpasses that of the larger Qwen2.5 model.
In the blog, Alibaba stated that the overall performance of the Qwen3 Dense base model is comparable to the Qwen2.5 base model with more parameters. For example, Qwen3-1.7B/4B/8B/14B/32B Base performs similarly to Qwen2.5-3B/7B/14B/32B Base.
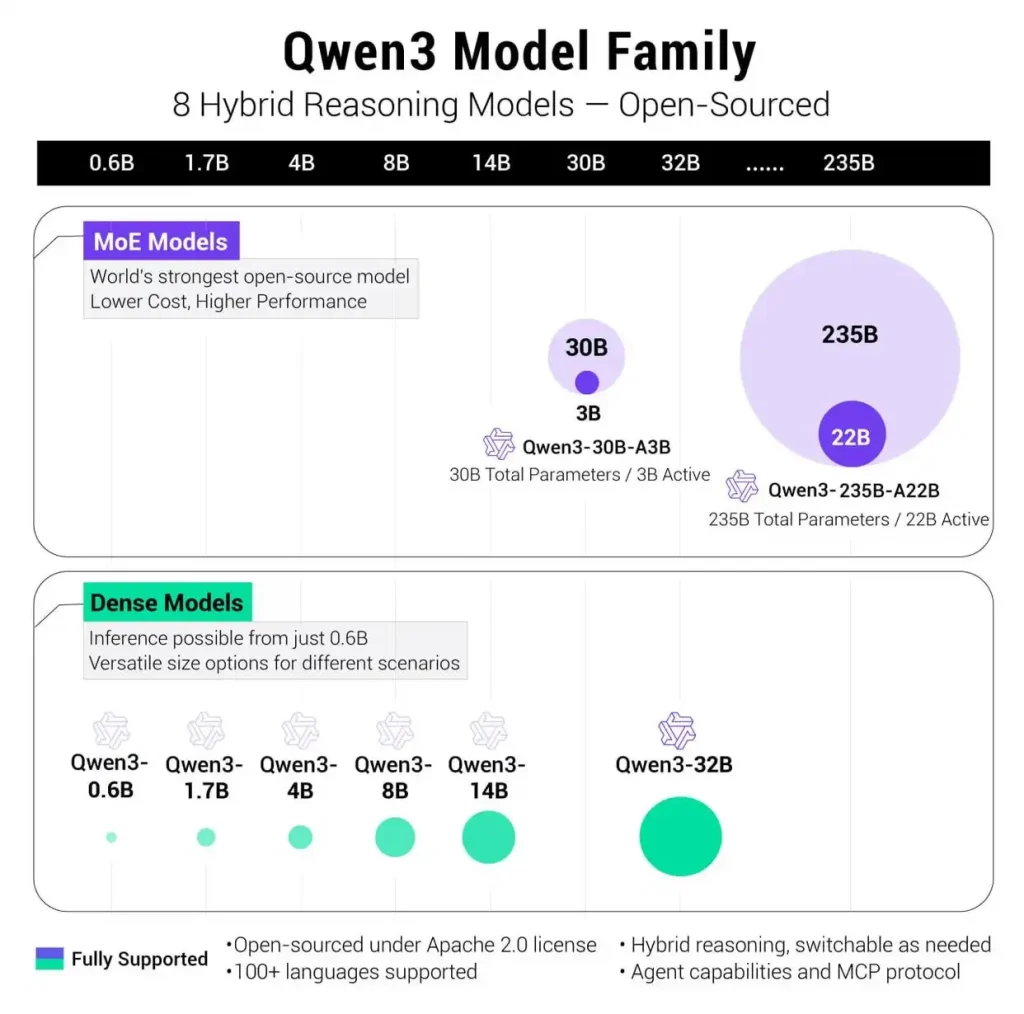
Interestingly, in addition to the MoE model with 235B parameters, Qwen 3 is also equipped with a small MoE model, namely Qwen 3-30B-A3B. The activation parameter count of this model is 3B, which is less than 10% of the QwQ-32B model, but its performance is even better.
We can understand the MoE architecture as a large customer service center with many experts dedicated to handling different issues – some experts specialize in technical issues, some experts handle billing queries, and some experts are responsible for answering product usage questions. In the process of training a large model, when data enters the model, the model will act like a “customer service center” and be assigned to the most suitable experts based on the nature of the problem to solve, which can improve the computational efficiency of queries.
This time, Alibaba’s source models include Dense model and MoE model. Among them, the weights of two MoE models were open sourced: Qwen3-235B-A22B, a large model with over 235 billion total parameters and over 22 billion activation parameters, and Qwen3-30B-A3B, a small MoE model with approximately 30 billion total parameters and 3 billion activation parameters.
Six Dense models have also been open sourced, including Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B, all of which are open sourced under the Apache 2.0 license. It can be directly commercialized.
One of the innovations of the Qwen 3 series is its “hybrid” model design, which seamlessly switches between slow thinking modes such as deep thinking (used for complex logical reasoning, mathematics, and coding) and fast thinking modes (used for efficient and versatile chatting), ensuring optimal performance in various scenarios.
This means that users no longer need to manually turn on and off the “deep thinking” function, and are worried about the problem of model overthinking. Previously, many users of large models have reported that large models often engage in deep thinking and output lengthy texts, and many small problems are completely unnecessary.
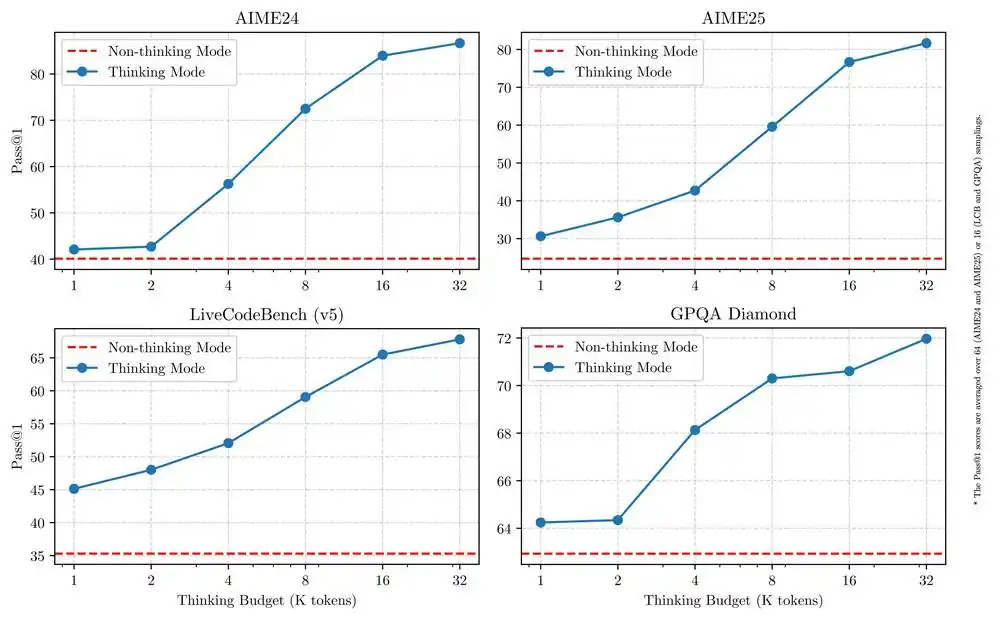
The key is that this flexible switching mode of fast and slow thinking can effectively reduce costs. Alibaba stated in its blog that the combination of these two modes greatly enhances the model’s ability to achieve stable and efficient “thinking budget” control. This design allows users to easily configure specific budgets for different tasks, achieving a better balance between cost-effectiveness and inference quality.
In terms of deployment, Alibaba claims that only 4 H20s are needed to deploy the full health version of Qianwen 3, and the graphics memory usage is only one-third of similar performance models. This means that compared to the fully blooded version of Deepseek R1, deployment costs have been significantly reduced by 75% to 65%.
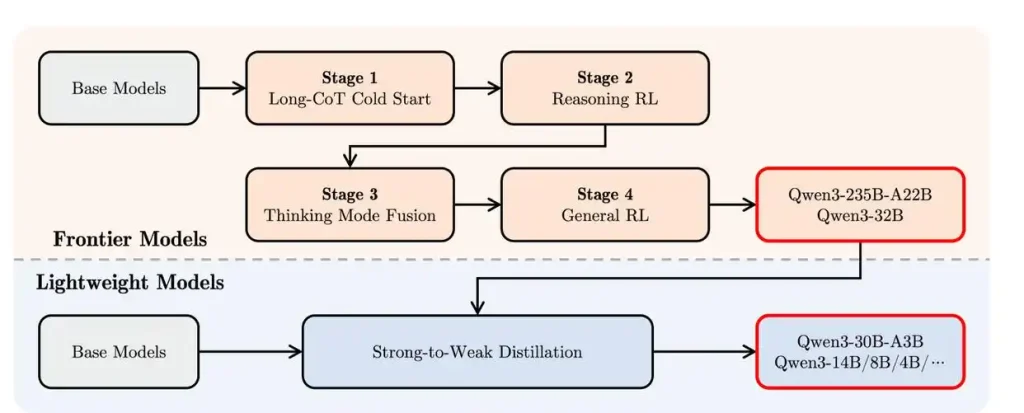
Alibaba introduced that Qwen3 has gone through a four stage training process, which is equivalent to teaching basics first, then practicing deep thinking, mixing fast and slow modes, and finally comprehensive optimization. Alibaba stated that Qwen3 performs excellently in tool invocation, instruction execution, and data format processing. It is recommended to use Qwen Agent in combination, as it can simplify the code implementation of tool calls.
This time, Alibaba also specifically optimized the Agent and code capabilities of the Qwen3 model, while also strengthening support for MCP. In the example, it can be seen that Qwen3 can smoothly call the tool.
Open source is becoming Alibaba’s core AI strategy. Starting from 2023, Alibaba’s Tongyi team has developed over 200 “full-size” large models covering parameters such as 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B, and 110B.